Equine Data Processing
This project comes from my partner who studies equine genetics. The research she’s working on involves analyzing horse performance based on a coefficient of inbreeding. There’s a specific company that sells horse pedigree records, categorizing large swaths of race history for a given horse’s offspring. This is perfect for the task. Unfortunately this data is sold on a per document basis, which is given in… PDF form.
This means in order to compile the data, several very talented biologists would have spent days for each horse they wanted data on, manually entering information into a spreadsheet.

So, this project, currently dubbed ‘Horsifier’, scans a bunch of PDFs and outputs the data to CSV.
Regex!
I only learned Regex out of necessity a few months ago for a class assignment, so I’m pretty proud of getting something this complicated off the ground. I doubt this is the most elegant solution, in fact I bet this pattern is full of very obvious issues, but it (mostly) works for now.
The data is generally formatted like this: 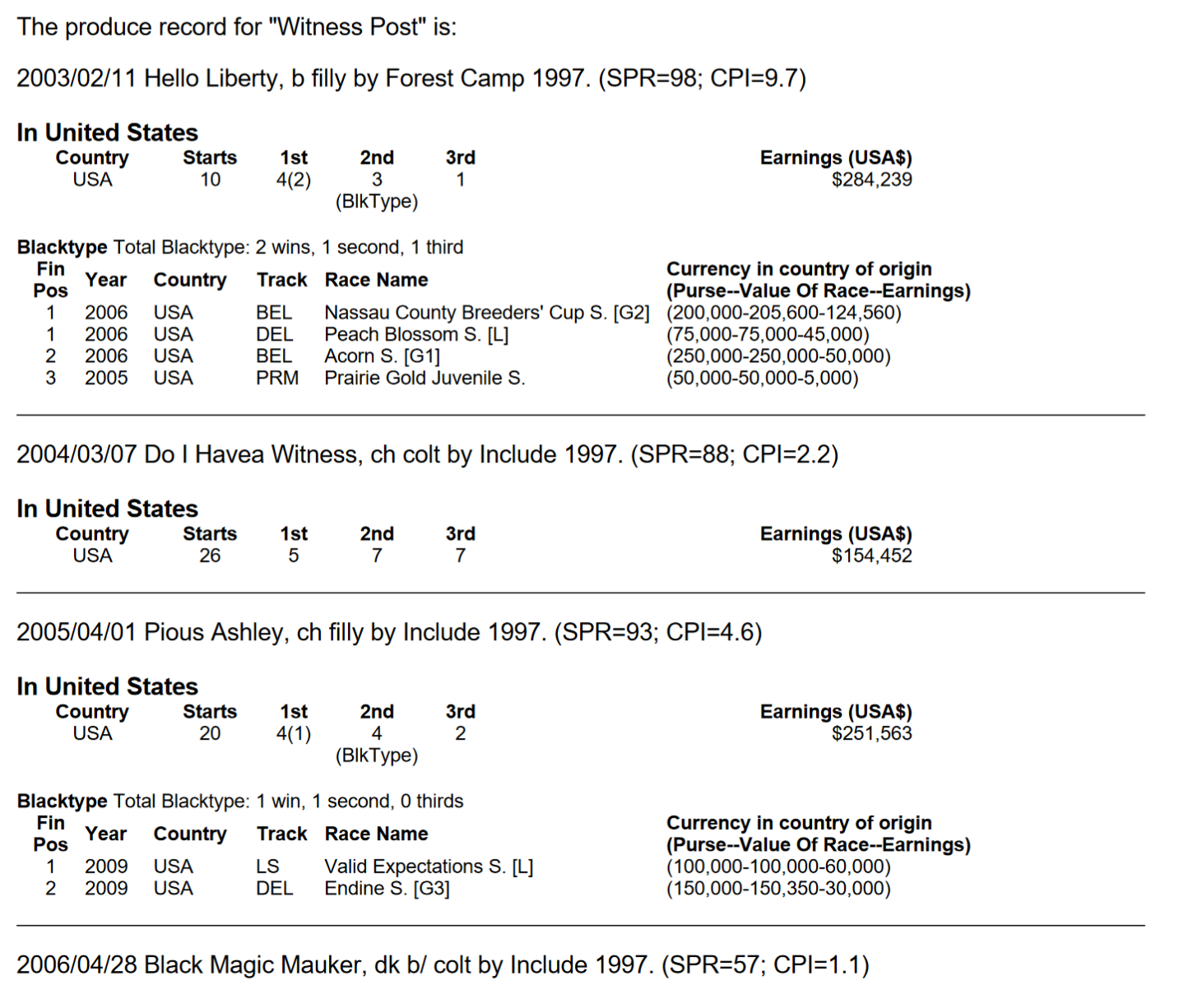 (Taken from a free sample PDF at https://www.equineline.com/samples/samp22P.pdf)
(Taken from a free sample PDF at https://www.equineline.com/samples/samp22P.pdf)
And a helpful diagram provided by my lovely partner: 
And while we want all of that information, I’m focusing just on extracting the data before the race statistics for now. As the size of the regex pattern increases, so does the probability of missing an entry. For a while, the only way I could detect bugs was by Ctrl+F different names in both the PDF and CSV until I caught a discrepancy, so I wanted to keep the scope small while I ironed out all the issues.
pattern = re.compile(r'''
((?!=)[^\n\\]{1,23}), # Foal name
\ ([^,]+), # Foal birthday
(\ [\w\s\/]+)? # Foal color (optional)
\ (colt|gelding|filly)\ -- # Foal sex
(?: # Anything below this can fail and still go through.
\ ([^\(]+) # Dam name TODO: Add 1,23, country code?
\ \((\d+)\) # Dam year
(?:\ \(SPR=(\d+); # Dam SPR (optional)
\ CPI=(\d+\.\d+)\))? # Dam CPI (optional)
\s([^\n\\]{1,23}) # Dam sire name
\ \((\d+)\) # Dam sire year
\s
# TODO: died capture, 'stands in ___'
#(?:Died\ in\ [\d+]{4}\s)?
(?:[^\n()]*)?
(?:\(SPR=(\d+);)? # Foal SPR
(?:\ CPI=(\d+\.\d+)\))? # Foal CPI
)?
''', re.VERBOSE)As you can see, there’s still a lot to work on here. Hopefully next post I’ll have that all figured out.